
Updated Grails Database Migration plugin
Friday, January 04th, 2013Edit: January 5 – I released the plugin that adds support for JAXB-based classes; see the plugin page and the documentation for more information.
and the documentation for more information.
One of the downsides to releasing a lot of plugins is lots of reported issues. I’ve joked that since there aren’t good ways to know how much use a plugin gets, the best metric is the number of reported bugs and feature requests, and that is mostly true. Using that logic the database-migration plugin is very popular 🙂
I try to address serious issues, but most of this plugin’s issue have to do with generated code. My attitude towards generated code is that it should not be trusted, and should rarely be expected to be completely correct. For example, when you use the dbm-gorm-diff or dbm-generate-gorm-changelog scripts, they do most of your work for you. My hope is that it saves you lots of time and that you shouldn’t need to do much work to fix any issues, but that you should expect issues.
When I did the What’s new with Grails 2.0 talk at NEJUG a year ago I mentioned this plugin and focused on the GORM-based scripts because I think they’re the best approach to creating migrations. But one of the attendees who also uses Rails said that Rails migrations were better because they have a DSL that you can use to write the migrations. I realized that I was so used to running dbm-gorm-diff that I had neglected to even mention the extensive Groovy DSL that the plugin supports (it’s a 100% clone of the XML syntax in native Liquibase). It’s a good DSL and you can create migrations completely by hand using it, but I can’t see why you would do that given how much you can get for free with the scripts. I mention this story to point out why I think it’s ironic when people complain that it’s tedious to have to fix invalid code that a script generated; feel free to use the DSL directly and forego the broken scripts 😉
The bug list for the database-migration plugin was getting a bit big and there were quite a few open pull requests. The tipping point however was seeing this tweet and realizing that I should spend some time on the plugin again.
The pull request that Zan mentioned in his tweet was a big one, adding support for doing migrations on multiple databases, mirroring the multi-datasource support in Grails 2.0. It would be great if all pull requests were this high-quality, including documentation updates and lots of tests. While I was integrating that (I had made some changes since then that required a traditional pull request since the Github UI wouldn’t do an automatic merge, and there were a few conflicts) I worked on the other outstanding issues.
I merged in all of the open pull requests – many thanks for those. I also closed a few bugs that weren’t real bugs or were duplicates, and fixed several others. That made for an interesting JIRA 30-day issue graph: 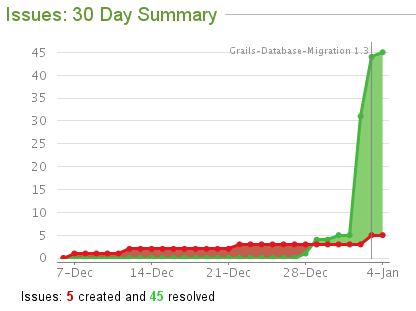
Many of the other reported issues were variants of the same problem where Liquibase was specifying the size of database columns that don’t support a size (for example bytea(255)). Hibernate does a much better job of this, so I was able to rework things so the Hibernate data types are used where possible instead of what Liquibase generates. So hopefully the generated changelogs will be much more accurate and involve less tweaking.
You can see the release notes of the 1.3 release here and the updated docs here.
Note that the latest version of the plugin is 1.3.1 since there were issues with the JAXB code that I included in the 1.3 release. I removed the code since it depends on Java 7 (and wasn’t completely finished) and will release it as a separate plugin.




