
Archive for September, 2008
links for 2008-09-19
Friday, September 19th, 2008A Grails-aware Log4j SMTP Appender
Wednesday, September 10th, 2008Proper logging implementation is a complex issue. If you log too much in production you risk wasting CPU and I/O time. If you log too little, you won’t have enough information to diagnose problems. And no matter how efficiently you implement your logging, if you don’t check your logs you won’t know when bad things are happening.
So here’s a Log4j appender that sends emails for messages logged at the
appender that sends emails for messages logged at the Error level or higher. Yes, Log4j comes with an appender that sends emails, org.apache.log4j.net.SMTPAppender. The one I present here is a little simpler, but more importantly it’s Grails-friendly. Specifically it doesn’t send emails unless the app is running in production mode. Error emails are great, but very annoying while debugging 🙂
import grails.util.GrailsUtil;
import org.apache.log4j.AppenderSkeleton;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.log4j.PatternLayout;
import org.apache.log4j.spi.LoggingEvent;
import org.codehaus.groovy.grails.commons.GrailsApplication;
/**
* Replacement for Log4j's SMTP appender that uses the mail service.
*
* @author Burt
*/
public class SmtpErrorAppender extends AppenderSkeleton {
/**
* Perform 1-time initialization.
*/
public static void register() {
if (!GrailsApplication.ENV_PRODUCTION.equals(GrailsUtil.getEnvironment())) {
// only configure for production
return;
}
SmtpErrorAppender appender = new SmtpErrorAppender();
Logger.getRootLogger().addAppender(appender);
Logger.getLogger("StackTrace").addAppender(appender);
}
/**
* Constructor with default values.
*/
public SmtpErrorAppender() {
setThreshold(Level.ERROR);
setLayout(new PatternLayout(
"%-27d{dd/MMM/yyyy HH:mm:ss Z}%n%n%-5p%n%n%c%n%n%m%n%n"));
}
/**
* {@inheritDoc}
*/
@Override
public void append(final LoggingEvent event) {
if (!event.getLevel().isGreaterOrEqual(Level.ERROR)) {
return;
}
event.getThreadName();
event.getNDC();
event.getMDCCopy();
mailService.sendErrorEmail(layout.format(event), event);
}
/**
* {@inheritDoc}
* @see org.apache.log4j.AppenderSkeleton#close()
*/
public synchronized void close() {
closed = true;
}
/**
* {@inheritDoc}
* @see org.apache.log4j.AppenderSkeleton#requiresLayout()
*/
public boolean requiresLayout() {
return true;
}
}
Unfortunately since this class will be compiled with the application code after Config.groovy is loaded, you can’t add it to the Config.groovy log4j section. Instead, just put some initialization code in Bootstrap:
class BootStrap {
def init = { servletContext ->
// can't put this in Config.groovy since the class won't have been compiled yet
SmtpErrorAppender.register()
}
}
Also, note that I’ve omitted the setter and declaration of ‘mailService’, which you’ll need to provide. The Grails mail plugin is good candidate. The details of what the email body looks like and who receives the emails is left as an exercise for the reader.
As I said, this is different from the standard email appender, so use that one if you prefer, but either way you should be using something to automatically notify yourself when errors are happening.
One consideration that’s important when implementing this is clarifying what you consider an Error-level or Fatal message. Ideally a Fatal error message should be severe enough that pagers start going off and phones start ringing (that’ll take another appender). So it’s important to decide what gets logged and at what level, so you don’t overwhelm yourself and support people with so many non-critical messages that they start ignoring them.
A Grails Memory Leak
Sunday, September 07th, 2008I’m in the process of building a large database to load-test our application at work. Index usage and execution plans are quite different with many rows than with a few, so I’m creating millions of rows in tables for domain classes that will see a lot of activity to find missing indexes, inefficient queries, etc.
I used the typical strategy for Hibernate batch processing – flush() and clear() the Session periodically to push the data to the database and free up memory used by domain instances. But even with a 1-gig heap, the process kept running out of memory after several hours, and was running very slowly for the last couple of hours – typically indicative of lots of garbage-collection thrashing.
Profiling the process using YourKit showed that domain instance counts were steadily increasing. Repeatedly running gc() had no effect on these instances, although it clearly ran since memory usage and other object counts dropped (note that calls to gc() can’t force garbage collection, it’s just a request).
The code and domain classes aren’t complicated and didn’t have any obvious couplings that could cause instances to not be garbage collected, and I kept ripping out more and more code to try to find what was causing the problem. Finally I got it down to the smallest code block that illustrated the problem:
for (int i = 0; i < 100000; i++) {
new Thing(name: "thing_${i}")
Thread.sleep(50) // to allow time to watch things in the profiler
}
I ran this in the Grails console and with Hibernate 2nd-level caching turned off, both in a transaction and not (to eliminate the transaction as the culprit). Just creating the instances and not saving them – in this code Hibernate isn’t involved at all – triggered the problem.
So I described the issue on the Grails User mailing list and after an interesting discussion Graeme mentioned that it had to do with the validation Errors objects. He suggested setting errors to null after the instances were no longer used, i.e
for (int i = 0; i < 100000; i++) {
Thing thing = new Thing(name: "thing_${i}")
thing.errors = null
Thread.sleep(50) // to allow time to watch things in the profiler
}
This should work in a web context, but I was working in the console, so I got a NullPointerException. The problem was clear when I looked at the MetaClass code in DomainClassGrailsPlugin:
static final PROPERTY_INSTANCE_MAP =
new org.codehaus.groovy.grails.support.SoftThreadLocalMap()
metaClass.setErrors = { Errors errors ->
def request = RCH.getRequestAttributes()?.request
def storage = request ? request : PROPERTY_INSTANCE_MAP.get()
def key = "org.codehaus.groovy.grails.ERRORS_${delegate.class.name}_${System.identityHashCode(delegate)}"
storage[key] = errors
}
metaClass.getErrors = {->
def request = RCH.getRequestAttributes()?.request
def errors
def storage = request ? request : PROPERTY_INSTANCE_MAP.get()
def key = "org.codehaus.groovy.grails.ERRORS_${delegate.class.name}_${System.identityHashCode(delegate)}"
errors = storage[key]
if(!errors) {
errors = new BeanPropertyBindingResult(
delegate, delegate.getClass().getName())
storage[key] = errors
}
errors
}
Instead of storing the Errors in the Request, which in the console doesn’t exist, it stores it in a Thread-local Commons Collections ReferenceMap. This map doesn’t accept nulls, so instead I had to access it directly, i.e.
DomainClassGrailsPlugin.PROPERTY_INSTANCE_MAP.get().clear()
This worked – memory usage was fine and I could see that instances were being garbage-collected while running under the profiler.
But this begs the question – why was I in this mess in the first place? Why are there Errors objects involved if I’m not calling validate() or save(), just creating new instances?
ControllersGrailsPlugin wires up a DataBindingDynamicConstructor that takes a Map to allow creating domain instances like this:
def foo = new Foo(prop1: 123, prop2: 'foo', prop3: new Date())
This dynamic constructor copies the map data using a GrailsDataBinder into the new instance in DataBindingUtils.bindObjectToInstance(), and at the end calls setErrors() passing the BindingResult (which implements Errors) generated from copying the data. These are stored in the Map (or as a Request attribute if running in a web context) and this ended up being the reference that kept the instances from being garbage collection candidates even though they were no longer in scope in the loop.
So, mystery solved. In the end this is all academic for me since I needed to get things working so I rewrote the data population code using JDBC (and Java) and it runs quite a bit faster than the equivalent Grails/Groovy/GORM code. This isn’t usually an issue for small web requests but for a process that takes many hours it definitely makes a difference.
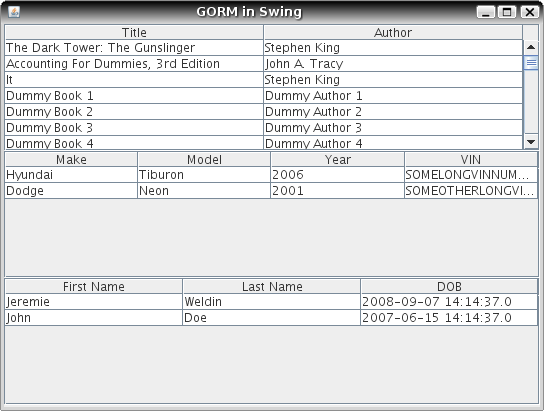
Using GORM outside of Grails part 2 – Swing
Sunday, September 07th, 2008In an earlier post I wrote about getting GORM to work outside of Grails. It worked, but wasn’t really usable since it could only execute script files, so its usefulness was pretty limited in a real application. Greg Bond replied on the mailing (here and here) with some great enhancements that allowed it to work without script files. So I fleshed that out some more and now have a working implementation and even a Swing application to demonstrate.
The key was that Greg used grails compile to generate his domain class files. I’d just been using the groovyc Ant task, and when I looked at what the Grails compile script the difference turned out to be that Grails uses a Grails-aware subclass of Groovyc, org.codehaus.groovy.grails.compiler.GrailsCompiler. It allows you to specify a resourcePattern attribute to point at the domain class .groovy files for special treatment.
So now instead of one sample project there’s three. One is the gorm standalone project, which creates a jar (gorm_standalone.jar) containing GormHelper which bootstraps GORM. The other two are the sample application, split into GORM domain classes and the Swing application. The domain class application contains the domain class .groovy files plus DataSource.groovy, and most importantly an Ant script that builds a usable jar (domainclasses.jar). The Swing application uses gorm_standalone.jar and domainclasses.jar as libraries and displays a simple UI showing the results of database queries.
Here’s a quick screen shot:
You can download the sample apps here:
GORM standalone app
Sample app domain class app
Sample Swing app
A Grails Plugin for Spring MVC Controllers
Sunday, September 07th, 2008I wrote earlier about using Spring MVC controllers in a Grails app. I was looking at that again since I thought it might be useful as a plugin. Unfortunately although it did work at the time, I ended up having to do a lot more work to get it going. I guess some things changed in intermediate Grails releases, and I didn’t save the code. But anyway, it’s working now 🙂
Installation
To use it in your app, install like any plugin:
grails install-plugin springmvc
The install script will create a web-app/WEB-INF/jsp folder if it doesn’t exist, and copy the sample error.jsp there if it doesn’t exist. It also creates an empty web-app/WEB-INF/SpringMVC-servlet.xml – the file has to exist but all beans are defined by the plugin or in the app’s resources.groovy and/or resources.xml.
Configuration
There are a few configuration options available – all are optional. They’re defined in a springmvc block in Config.groovy:
| Name | Default Value | Description |
|---|---|---|
| urlSuffix | ‘action’, i.e. *.action |
the URL pattern for Spring MVC controller URLs |
| exceptionMappings | none | Map with exception class names as keys and JSP names as values |
| defaultErrorView | ‘error’, i.e. web-app/WEB-INF/jsp/error.jsp |
the default error page if there’s no corresponding mapping for the exception class |
| interceptors | none | bean names of HandlerInterceptors to apply to Spring MVC URLs |
So a configuration block that defines a single interceptor, uses *.action for URLs, and defines a default error JSP and two exeption-specific exception mappings (note that the values for urlSuffix and defaultErrorView are redundant since they’re the default values) would be:
springmvc {
interceptors = ['loggingInterceptor']
exceptionMappings = ['java.io.IOException': 'ioexception']
exceptionMappings = ['com.myapp.MyException': 'myex']
defaultErrorView = 'error'
urlSuffix = 'action'
}
Application Beans
Unlike in Grails, there’s no automatic URL mapping. To connect a controller to a URL you define a Spring bean (in resources.groovy or resources.xml) whose name is the url and the bean class is the controller, e.g.:
'/test.action'(com.burtbeckwith.mvctest.controller.TestController) {
cacheSeconds = 0
bookService = ref('bookService')
}
This will map http://localhost:8080/yourapp/test.action to TestController. Setting cacheSeconds to 0 instructs Spring to send headers to disable caching. And ‘bookService’ is a dependency injection for BookService to access Book domain instances. The controller returns ‘books’ as it’s view name – this is prefixed by ‘/WEB-INF/jsp/’ and suffixed by ‘.jsp’ to define the JSP that will render the response (i.e. ‘/WEB-INF/jsp/books.jsp’).
You can also define HandlerInterceptors in resources.groovy. They should extend HandlerInterceptorAdapter or implement HandlerInterceptor directly. Add their bean names to the ‘interceptors’ list and Spring MVC requests will be intercepted. Note that these interceptors are in addition to the standard Hibernate OSIV interceptor and a locale change interceptor.
For example:
loggingInterceptor(com.burtbeckwith.mvctest.interceptor.LoggingInterceptor)
Sample App
You can download a sample app here. It’s pretty simple – it has a single domain class, and a single Grails controller and a Spring MVC controller (to test that both work in the same app). There’s a Grails service to access domain instances that implements a Java interface so it’s callable by the MVC controller. There’s also a sample interceptor (it just logs requests) and a sample JSP 2.0 tag file, date.tag.
The app creates six books in Bootstrap – you can see the data by going to http://localhost:8080/mvctest/test.action. Go to http://localhost:8080/mvctest/regular to access a regular Grails controller.
A Grails Plugin for Multiple DataSources
Thursday, September 04th, 2008There have been a few requests on the Grails user mailing list about using multiple data sources in a Grails app, i.e. some domain classes use one data source and database and others use another. Grails doesn’t directly support this – there’s only one DataSource and one SessionFactory, and all domain classes use them. But it turns out it’s not that difficult to support this (and it doesn’t involve too many ugly hacks …)
There are some implications of the approach I took. This doesn’t provide XA transactions, 2PC, etc. It’s just a partitioning of classes between two or more datasources. The way it works is to run after the HibernateGrailsPlugin and DomainClassPlugin have done their work. Then it uses a configuration defined in grails-app/conf/Datasources.groovy and creates one or more extra DataSource, SessionFactory, TransactionManager, etc. and re-runs the HibernateGrailsPlugin‘s doWithDynamicMethods closure for the appropriate subset of domain classes. This way when you call a magic GORM method (e.g. list(), get(), findByNameAndDate(), etc.) it will use the correct underlying datasource. Any domain class not defined as using a secondary datasource will use the ‘core’ datasource defined in DataSource.groovy.
Another issue is that all domain classes stay defined in the core datasource/SessionFactory – the existing behavior isn’t changed, other than redefining the metaclass methods to use another datasource. The only effect of this is that if you use dsCreate = ‘create-drop’ or ‘create’ or ‘update’ for the core datasource, all tables will be created in the core database even though some won’t be used.
Datasources DSL
The DSL used in Datasources.groovy is very similar to the format of DataSource.groovy. One difference is that the ‘hibernate’ section is inside the ‘datasource’ section, and there are a few extra attributes.
| Name | Type | Required | Description |
|---|---|---|---|
| name | String | yes | datasource name, used as a Spring bean suffix, e.g. ‘ds2’ |
| readOnly | boolean | no, defaults to false | if true, the datasource and corresponding transactional services will be read-only |
| driverClassName | String | yes | same as in DataSource |
| url | String | yes | same as in DataSource |
| username | String | no | same as in DataSource |
| password | String | no | same as in DataSource |
| dbCreate | String | yes | same as in DataSource |
| dialect | String or Class | yes (no autodetect) | same as in DataSource |
| jndiName | String | no | same as in DataSource |
| pooled | boolean | no, defaults to false | same as in DataSource |
| loggingSql | boolean | no, defaults to false | same as in DataSource |
| logSql | boolean | no, defaults to false | same as in DataSource |
| environments | List<String> | no, defaults to [‘development’, ‘test’, ‘production’] | list of environments this DataSource should be active in |
| domainClasses | List<String> or List<Class> | yes | the domain classes that should use this DataSource |
| services | List<String> | no | short names of the services that should use this DataSource (same as Spring bean without ‘Service’, e.g. ‘user’ for UserService) |
See the sample app (link below) for a usage example.
OpenSessionInView
An OpenSessionInViewInterceptor is defined for each datasource, so the features that it provides are available to all domain classes. For example you can load a domain instance and set a property, and it will be detected as dirty and pushed to the database. Also, lazy loaded collections will load since there’s an active session available.
Further, if you save, create, load, etc. domain instances from multiple datasources in one controller method, all will work fine.
Transactional Services
By default, any service defined as transactional will use the core datasource. If you want a service to use a specific datasource, add its name to the ‘services’ attribute for a datasource definition. If there’s no one datasource for a particular service, you can still define programmatic transactions using withTransaction on any domain class for the appropriate datasource for each method or code block.
HibernateTemplate
I can’t think of non-contrived reasons to do so, but it’s possible to use a domain class in two or more datasources. The problem here is that the metaclass methods will end up mapped to the last declared datasource, so there’s no way to use GORM for the other datasource(s). However you can use Spring’s HibernateTemplate yourself – it has a lot of the functionality of GORM (GORM uses it under the hood). You can use the convenience method DatasourcesUtils.newHibernateTemplate(String dsName) to create a HibernateTemplate configured with the SessionFactory for the named datasource.
Usage
You might want to use this plugin even if you have only one database. Since you can define a datasource as being read-only and point read-only domain classes at it, your prevent yourself from accidentally creating, deleting, or updating instances.
I’ve created a basic (and rather contrived) test application. It has three datasources and five domain classes:
Country,StateLibrary,BookVisit
Country and State are just lookup tables, so they use a read-only datasource. Visit has a weak foreign key to Library, but this is not enforced since they’re stored in two databases. It’s the responsibility of the application to ensure that the library id for each visit is valid. This is to simulate having a second database for auditing.
To test the app:
- Create the databases using the scripts (ddl_core.sql, ddl2.sql, and ddl3.sql)
- run ‘grails run-app’
- Create a new Library at http://localhost:8080/ds_test/library/create
- Create a new Book at http://localhost:8080/ds_test/book/create
- check the database to ensure they ended up in the correct database
- Create a new Visit at http://localhost:8080/ds_test/visit/create
- check the database to ensure it ended up in the correct database
- edit a State at http://localhost:8080/ds_test/state/edit/1, save, and note that change didn’t take effect due to read-only datasource
- create a State at http://localhost:8080/ds_test/state/create, save you should see the error page due to read-only datasource
- test transaction failure at http://localhost:8080/ds_test/transactionTest/fail – you should see the error page and if you check the database nothing should have been inserted
- test transaction success at http://localhost:8080/ds_test/transactionTest/succeed – you should see a simple success message and if you check the database the inserts should have succeeded
If you want to manually manage the tables in each database instead of letting Hibernate do it for you, you can use the schema-export script from here to capture the DDL for all the tables. Then you can execute the DDL statements for each database separately.
The plugin is in the Grails repository, so to use it just run “grails install-plugin datasources”. You can download the test application here.




